2020语言与智能技术竞赛结果揭晓:追一科技登顶关系抽取任务榜首
2020-06-22 追一科技
近日,2020年语言与智能技术竞赛最终战报出炉,追一科技AI Lab团队再获殊荣,在“关系抽取”竞赛任务上,凭借优秀的模型表现,一举拿下冠军名次。在上年度的竞赛中,追一科技在“知识驱动对话”任务中夺冠。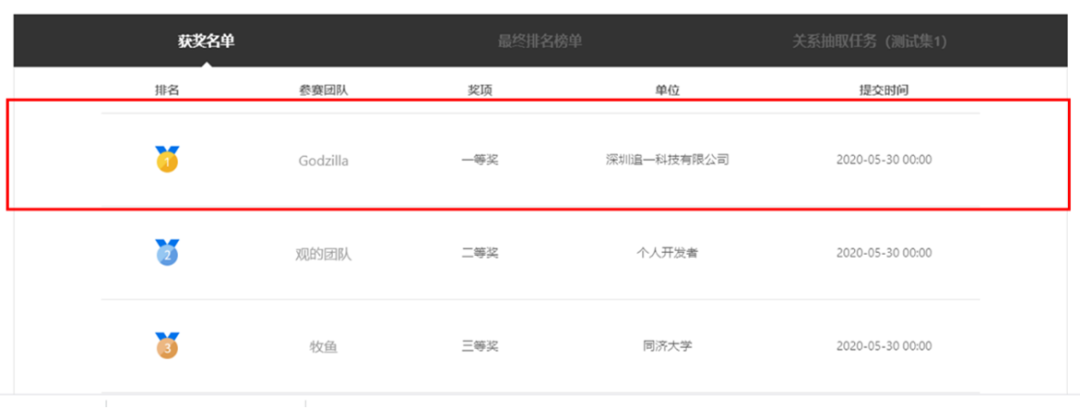
本届语言与智能技术竞赛由中国中文信息学会(CIPS)、中国计算机学会(CCF)以及百度公司联合主办,共设立五大任务——机器阅读理解、面向推荐的对话、语义解析、关系抽取和事件抽取,涉及语言理解、人机对话、知识抽取等复杂技术。
其中,关系抽取任务是信息检索、智能问答、智能推理等人工智能应用的重要基础,极具挑战性,一直受到业界的广泛关注,也是本届比赛难度最高、竞争最为激烈的任务之一。
关系抽取
让AI读懂非结构化数据
我们日常生活和工作中的文字文档、电子表格、演示文稿等文本文件,以及电子邮件、社交媒体数据、天气预报等等都是非结构化或半结构化的数据,计算机系统是无法识别和处理的。只有少部分的结构化数据,比如关系数据库等,计算机才可以识别并且利用。
AI的发展,让非结构化数据的利用上了一个新台阶。我们在《信息爆炸时代如何“大海捞针”?追一科技携手NLPCC推出“信息抽取”挑战任务》一文中曾提到,利用信息抽取技术可以从海量无结构或半结构化文本中,抽取出特定信息,以及信息之间的相互关系,帮助我们将海量内容自动重构为结构化数据,从而快速准确地获取需要的信息。
而关系抽取技术是信息抽取最重要的基础技术之一,主要负责从文本中识别实体并抽取实体之间的语义关系,组成(实体1,关系,实体2)的结构化“知识三元组”。
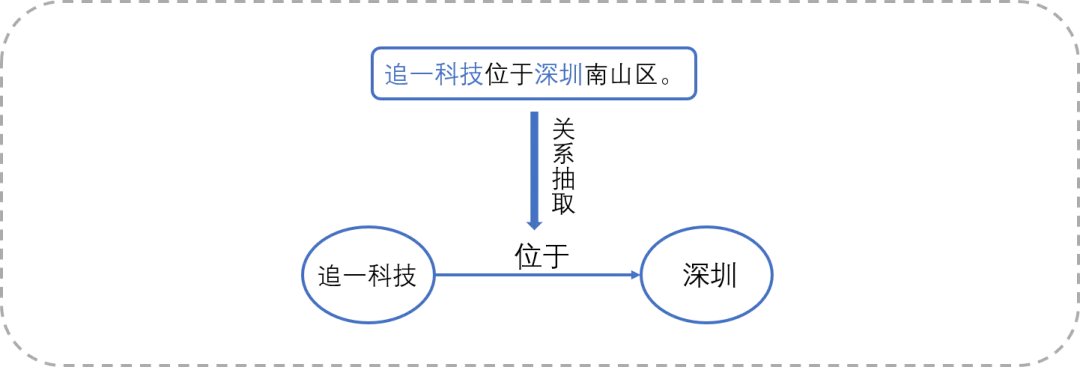
举个简单的例子:
针对非结构化文本「追一科技位于深圳南山区」,模型可以通过语义识别抽取出「追一科技」和「深圳」两个实体,以及「位于」的关系,并最终得到(追一科技,位于,深圳)的“知识三元组”。
这种简单的文本比较容易识别抽取,但实际文本多元复杂,一段文本可能存在多个实体,多个实体间又对应着多种不同的关系。
例如文本:
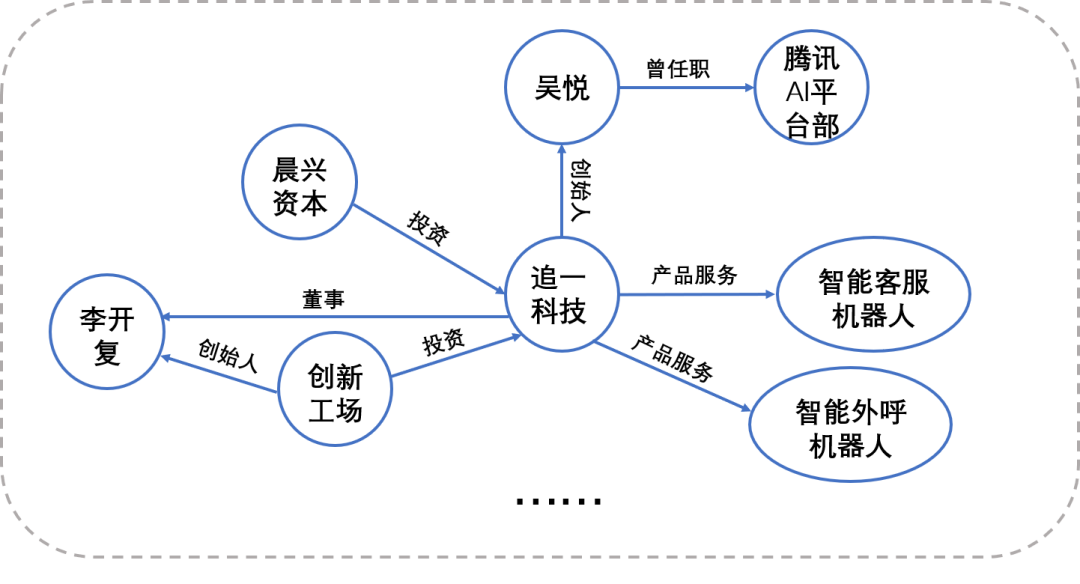
“追一科技是领先的AI公司和AI数字员工提供商,主攻深度学习和自然语言处理,提供智能语义,语音和视觉的AI全栈服务。追一科技先后获得了晨兴资本、高榕资本、创新工场、GGV等资本力量的投资,打造出以在线机器人、语音机器人、智能培训师、智能分析师、多模态虚拟人等为基础的产品矩阵……”
以上文本中不仅出现了「追一科技」、「晨兴资本」、「在线机器人」等实体,不同实体间还存在「投资」、「产品」等关系,模型在对这种多实体、多关系文本进行关系抽取时,便很容易错误匹配,或者遗漏某些实体间的关系,从而输出错误的、不完整的“知识三元组”,这也成为业内的挑战。
登顶之路
追一科技AI Lab团队面对这些挑战,采取了创新方法,将整个关系抽取任务分为主语抽取,宾语抽取和关系分类三个子任务。
相对于先抽取实体再关系分类的传统方案,团队把实体抽取任务分为主语抽取和宾语抽取,这样可以有效解决实体进行两两配对关系时带来的大量负样本问题。主语和宾语抽取的输出层采用机器阅读理解(MRC)中的指针网络(Pointer-Network)作为基本结构。为了支持多片段抽取,模型训练时将“多分类+交叉熵”的结构改为“二分类+交叉熵”的结构来预测头指针和尾指针。关系分类则采用多标签分类,这样可以解决多主语同一宾语,同一主语多宾语和同一主宾多关系的现象。同时,为了训练方便并提高效果,三个子任务共享BERT表达层,采用MT-DNN的多任务联合训练框架。
最后,在模型调优阶段,为了增强Transformer编码器的特征抽取能力,采用Talking-Heads Attention机制使Transformer的Multi-Head Attention中的head联系起来,有效提升了模型的表现。另外,针对本次任务中训练情况和数据分析时发现的正样本标注不完全的情况,采用PU Learning(Positive-unlabeled Learning)的思想进一步提升了模型的表现,最终在竞赛中取得了冠军。
探索行业应用
通过关系抽取技术提炼出隐藏在文本中的“知识三元组”后,到底有什么具体的作用呢?
前面提到,关系抽取任务的一个重要作用就是将海量的无结构化或半结构化的数据,抽取重构成结构化的数据。换句话说,通过关系抽取技术,可以将日常工作生活等产生的海量无结构化或半结构化数据“翻译”成计算机可以理解并处理的结构化数据。
而这种经过关系抽取得到的结构化数据组合在一起,被叫做——知识图谱。
知识图谱是一种基于图的数据结构,采用了人类容易识别的字符串来标识各元素,每个节点表示通过关系抽取技术得到的“实体”,每条边表示实体与实体之间的“关系”;同时,图数据表示作为一种通用的数据结构,很容易被计算机识别和处理。通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,旨在提供从“关系”的角度去分析问题的能力,所以关系抽取技术是构建知识图谱的关键技术之一。
具体举例来说,在零售领域,追一科技曾联手某全球知名的汽车制造商,打造了基于知识图谱的智能客服解决方案。
通过关系抽取技术和语义识别,追一科技的智能机器人Bot能将原本需要手动录入的车辆属性和经销商信息抽取出来,构建知识图谱,告别了手动添加海量业务信息的过程,提高信息更新效率,降低运维成本;另一方面,基于不断更新的知识图谱进行智能问答的客服机器人Bot,不仅可以支持诸如“A型车的价格”之类的基础问询,还能应对“30-60万的进口车有哪些”等多条件选车以及“A型车和B型车哪个便宜”等车型对比的常见咨询场景,相比传统智能客服的能力大大提升。
在AI辅助医疗领域,关系抽取技术可以抽取患者病症信息中的关键特征,排查医生可能会忽略的潜在并发症等隐性关系,提醒患者或医生提供相关病症补充,进行必要的检查,从而更加精准地分析患者病情。
在金融风控领域,关系抽取技术可以帮助快速构建以企业、自然人、业务、经营情况、公司动态等为实体,相互关联关系为边的知识图谱。通过对图谱分析,金融机构可以监控企业及其关联企业,评估其经营情况、公司动态、潜在风险,完善贷前贷中授信,降低不良贷款率,满足金融信贷风控需求。
随着人工智能在各行各业的落地和应用,对知识图谱的需求场景也越来越多,关系抽取技术将是快速构建知识图谱的“得力助手”之一。尽管目前关系抽取技术还有些挑战,我们有理由期待,随着不断突破与成熟,这门技术在未来人工智能应用中将成为“中流砥柱”。
Copyright© 2016-2024 Zhuiyi 深圳追一科技有限公司
粤ICP备16046705号