追一科技超越Facebook,在"超难考卷"上跃居全球第二
2020-01-13 小一
近日,追一科技AI Lab团队在最新自然语言处理领域权威数据集SuperGLUE中超越Facebook AI,跃居榜单第二。值得注意的是,此次登榜的RoBERTa-mtl-adv模型的相关技术已经落地到追一科技的AI数字员工产品线上,持续赋能银行、保险、证券、零售、地产、能源,教育,互联网等多个行业。

什么是SuperGLUE?一份超难的“考卷”
SuperGLUE(Super General Language Understanding Evaluation)是当下NLP领域难度最大,权威性最高,含金量最足的测评标准之一,由纽约大学、华盛顿大学以及谷歌旗下的DeepMind联合Facebook作为主要发起人推出,旨在更真实地反映当前最前沿的NLP技术可以达到的认知智能水平。
作为曾经自然语言处理领域的最权威的测评标准之一,GLUE在短短一年多时间里接连被百度、微软、谷歌、Facebook等“学霸”们刷新榜单头名的位置,并且综合评分都超过了人类水平。值得为技术进步喝彩的同时,急需新的“考卷”让“学霸”们重新一较高下——SuperGLUE应运而生。
从SuperGLUE的任务集来看,研究人员主要从任务集的多样性和单个任务集的难度两个方面对GLUE进行了改进。研究人员仅保留了GLUE原9项任务中的2项,不仅去掉了模型能轻易获得高分的任务,还新增了5个难度更大的任务,形成了包括问答任务、自然语言推断任务、词态消歧任务,指代消解任务,常识推断任务等在内的几大任务,最大程度涵盖了现实生活中可能遇到的不同类型的NLP任务,成为衡量各机构NLP技术水平最重要的指标之一。
从榜单结果来看,谷歌T5,Facebook AI,IBM AI,斯坦福大学等在内的顶级研究团队(学霸们)纷至沓来,但截止目前为止,还没有任何一个模型在SuperGLUE上的综合评分能够超越人类水平,并且分差还不小。SuperGLUE也坐实了NLP领域“最难”数据集的盛名。
最初设计GLUE的目的是为了尽可能地覆盖 NLP全领域,从而只有开发出足够通用的模型,才能在GLUE测试数据集上表现良好;而SuperGLUE是从比GLUE更宽广、更复杂、更难的语言理解维度来考察NLP模型的能力,因此只有更通用、更智能的模型,才能在SuperGLUE上“金榜题名”。
追一跑出商用模型最高水平
追一科技在为企业提供智能交互服务的过程中,技术和应用互相驱动,将实际商业化应用中总结出的多任务学习、对抗训练、知识蒸馏等技术手段和经验融入到参赛模型中,并在SuperGLUE测评数据集上拿到第二的成绩。具体来说,追一科技在此前针对业务场景的技术方案中就曾利用过多任务学习来提升模型的泛化能力,多任务学习的方法此次同样适用,在SuperGLUE中,不同的任务之间进行多任务学习可以提高在各自任务上的表现。此外,这次的方案中还利用了对抗训练来进一步增加模型的效果。加入对抗训练的也是来自在业务项目中进行的积累和经验,因为在生产环境中,模型的输出结果容易受到微小的干扰而判断出错,研究员基于过往的技术经验,采用对抗训练的方式来增强模型的鲁棒性(抗干扰能力)。除了多任务与对抗训练外,为了在不增加模型体积的同时让模型尽可能地获得更多的知识,还针对部分数据集采用了知识蒸馏,其目的是减少模型融合时所用的模型个数。
小贴士:(希望深入了解可以点击相应位置参考我们此前的技术文章)
多任务学习:让模型同时进行多个相关联的任务的学习,使得各个任务之间相互促进以提升模型的整体效果。可以理解为学习数学的同时学习物理,数学工具给物理公式的推导奠基,物理公式的推导夯实了对数学的理解。
泛化能力:可以理解为模型举一反三的能力。
鲁棒性:可以理解为模型抗干扰的能力。干扰有各种各样的情况,以文本为例子,其有可能是错别字、词,也可能是语音识别转文字过程中带来的错误等。例如在交互过程中将“改签”误听成”改天”等
知识蒸馏:指的是一种将已经训练好的模型所学的知识“蒸馏”出来后,再融入到一个新模型当中让新模型具备这些知识的技术。(小Yi也想习得这种“简单粗暴”的知识迁移术)
目前排名榜单第一的是Google的T5模型。从学术研究看,T5模型达到了目前“实验室智能”的最好水平,但如果考虑商用,T5需要耗费大量的算力,且模型自身体积过于庞大,目前还不能落地到实际业务场景中,缺少实际的商业应用价值。而追一科技通过多任务学习、对抗训练以及知识蒸馏的方式,使得RoBERTa-mtl-adv模型大小合理,效果仅次于Google的T5。同时,相关技术也落地到了追一科技AI数字员工的产品线上。就SuperGLUE排名而言,可以说追一科技的RoBERTa-mtl-adv模型在目前全球具有实际落地能力的NLP模型中效果最好,排名最高。(请继续关注公众号,更多技术详情会随后更新)
模型的相关技术如何应用?
SuperGLUE中的测试项目并非是“花拳绣腿”,而是实实在在考验模型通用能力的“铁人三项”;参加SuperGLUE也并非只是为了刷新评分,更重要的是检验当前技术能否很好地落地到实际应用场景中去。
SuperGLUE覆盖了问答、推断、语义理解、常识判断等自然语言理解维度,是人机智能交互过程中的核心环节,在具体的业务场景中都有很重要的应用价值。追一科技此次参赛模型的相关NLP技术已经被成熟运用于到自主研发的全套AI数字员工产品线上,广泛服务于银行、保险、泛互联网、地产、政企等多个行业的标杆客户。例如,在追一科技的智能在线机器人Bot中就融入了多轮问答技术、语义检索、机器阅读理解技术等NLP技术,能准确识别用户意图,满足用户需求。
口说无凭,接下来我们就结合SuperGLUE中的任务与Bot的具体案例,一探虚实。
单/多轮问答技术是实现交互的基础技术支撑,例如下面这个智能在线机器人Bot服务餐饮行业的场景:

智能在线机器人Bot不仅可以从对话中准确识别出地点,人数等信息,还能进一步追问用户未给出的“用餐时间”的信息,满足客户的需求。而传统的客服机器人并不会对未给出的潜在信息做出反应。
机器阅读理解技术则可以针对无结构化文档进行问答,解决企业中大量关于文档或文件内容的客户询问。例如在金融保险领域会涉及到大量保险业务文档的修订、新增等情况。在面对客户时,即使是富有经验的客户经理,往往也很难迅速结合所有新增的文档内容进行有效回答。这时,定制了阅读理解技术的智能在线机器人Bot就又可以发挥作用了——可以实时帮助业务人员,针对相关问题从新文档中提取出答案,解决问题,降低出错的概率。
自然语言推断任务则关注文本之间的相互关系,通常被用来考察模型对文本的推理能力与语法理解程度。SuperGLUE中的RTE数据集,就是专门测试模型对文本蕴含的处理能力。而文本蕴含在实际用语中非常地普遍,模型是否能够有能力进行正确的判断至关重要,考虑下面这个银行领域的例子:
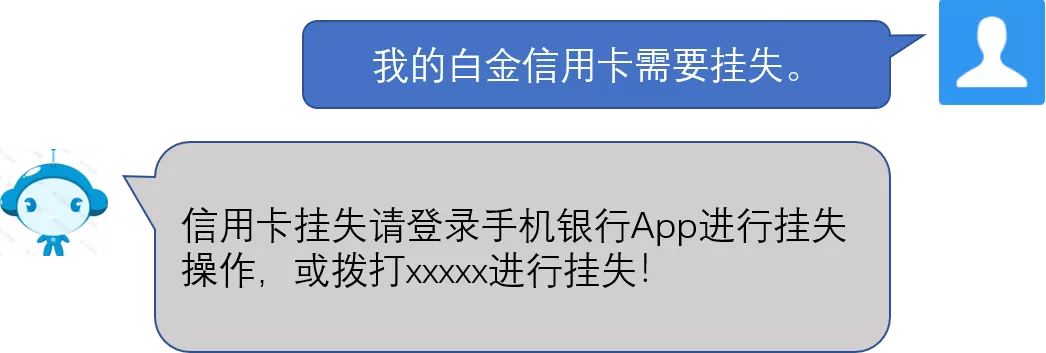
因为白金信用卡属于信用卡,因此“我的白金信用卡需要挂失”蕴含在“我的信用卡需要挂失”中,因此,智能在线机器人Bot 在回答用户时只需准确指引用户如何挂失信用卡即可。
指代消解任务是最基础的自然语言理解任务之一,它关系到对多句话的整体理解能力。在人的交流过程中,时常会有指代,在表达中适当地使用指代会让表达更加简练却不影响本意的阐述。如下面这个出行领域的例子:

智能在线机器人Bot理解了客户问句里的“上次”其实指代的是“上次中途取消订单”,所以立马给出了正确回复。
然而,最难为机器人的是常识推断任务,对语言的理解离不开对常识的掌握,SuperGLUE中的COPA数据集则是专门针对常识性因果推理能力进行考察的数据集。
例如COPA中的一个例子是:
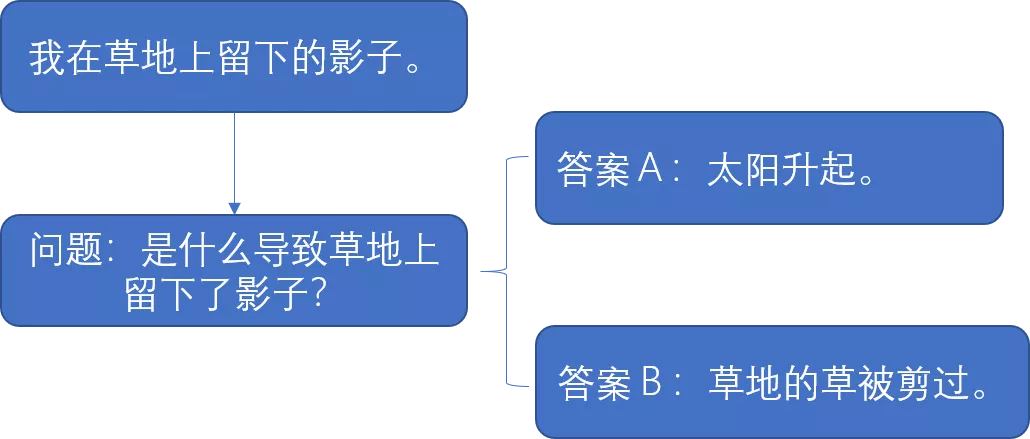
模型需要具备“影子是由太阳升起照射留下的”这样的常识性推断,才能正确的选择答案。对于人来说,这些常识很简单,但是对于机器来说,大量的这种常识知识都潜藏在我们意识的深处,AI系统的研究者几乎不可能把所有这样的常识都总结出来,并灌入到系统中,所以机器人在该数据集的表现就无法像人类一样拿到满分。落地到现实场景中,比如我们可以对智能在线机器人Bot说“我银行卡弄丢了”,Bot就会询问你是否需要挂失。因为它具备了“弄丢银行卡需要挂失”这样的常识。
可以看到,真实的交互场景中模型需要对语言的不同维度都具有理解能力才能完全正常流畅的对话。而上述的几个例子中的问题形式都很好地包含在了SuperGLUE的不同数据集中,因此,此次追一科技在SuperGLUE测评指标上获得的成绩,不仅是对其RoBERTa-mtl-adv模型在理解自然语言技术上的一个肯定,还验证了“技术驱动应用,应用导向技术”策略的可行性,更加坚定了追一科技继续深耕技术,持续用AI赋能百业的信念。
Copyright© 2016-2024 Zhuiyi 深圳追一科技有限公司
粤ICP备16046705号